These notes are from the early stages of the Young Lives Linked Data Demonstrator and are maintained here as an archive only.
Contents |
Young Lives Data Demonstrator
Working with data from the Young Lives project we are aiming to identify:
- How such datasets can be published as linked open data;
- What issues arise in the process of publishing the data;
- What sorts of things become possible once the data is published as linked and open data;
Development Environment
Exploring the data
Data from the Young Lives project is available in SPSS files through the UK Data Archive.
The free and open-source R statistical software can read SPSS files using the 'foreign' package (alternatively, PSPP is an open source clone of SPSS). With a young lives data file in the current working directory, the following commands can be used to convert the SPSS file to CSV which is easier to work with in most data conversion processes.
install.packages("foreign")
install.packages("Hmisc")
library(foreign)
library(hmisc)
fulldata<-spss.get("DataMashup_Peru_FullData.sav",use.value.labels=TRUE)
write.csv(fulldata,file="datafile.csv")
Once you have a CSV file you can explore the data in spreadsheet software or a tool such as Freebase Gridworks. Within R the following commands may be useful:
> library(Hmisc) > describe(fulldata) #Show the questions asked for each variable; > summary(fulldata) #Show a summary of the available data;
Modelling the data as RDF involves:
- Choosing how to represent individuals in the dataset
- Choosing how to represent variables
- Choosing how to represent questions
Initial modelling decisions
The below gives an example of a very rough-and-ready attempt to model a question from a Young Lives dataset in RDF:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix definitions: <http://younglives.practicalparticipation.co.uk/ontowiki/younglives/defn#> .
@prefix questions: <http://younglives.practicalparticipation.co.uk/ontowiki/younglives/questions/> .
@prefix answers: <http://younglives.practicalparticipation.co.uk/ontowiki/younglives/answers/> .
@prefix younglives: <http://younglives.practicalparticipation.co.uk/ontowiki/younglives/items/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
<younglives:individual/2>
a younglives:individual ;
definitions:gender <dbpedia:Female> ;
definitions:age "15" ;
questions:ableToSpeakAboutViewsAndFeelingsToParentsOrGuardians <answer:CertainlyTrue> ;
questions:mostlyParentsTreatFairlyWhenDoneWrong <answer:NA> .
<question:ableToSpeakAboutViewsAndFeelingsToParentsOrGuardians>
rdfs:label "You feel able to speak about your views and feelings with your parents/guardians" ;
definitions:relatedQuestions "younglives:questions/mostlyParentsTreatFairlyWhenDoneWrong" ;
definitions:hasAnswer <answer:CertainlyTrue>, <answer:NA>, <answer:NotTrue>, <answer:AnswerRefused> .
<answer:CertainlyTrue> rdfs:label "A little true for you" .
<answer:NA> rdfs:label "NA" .
<answer:NotTrue> rdfs:label "Not true for you" .
<answer:AnswerRefused> rdfs:label "Refused to answer" .
The graph below (geneated with [RDF Gravity) gives a visual representation of the RDF statements above. You can see the individual respondent and their demographics to the top-left of the diagram, their question answers towards the middle, and the question to which those answers may belong on the right.
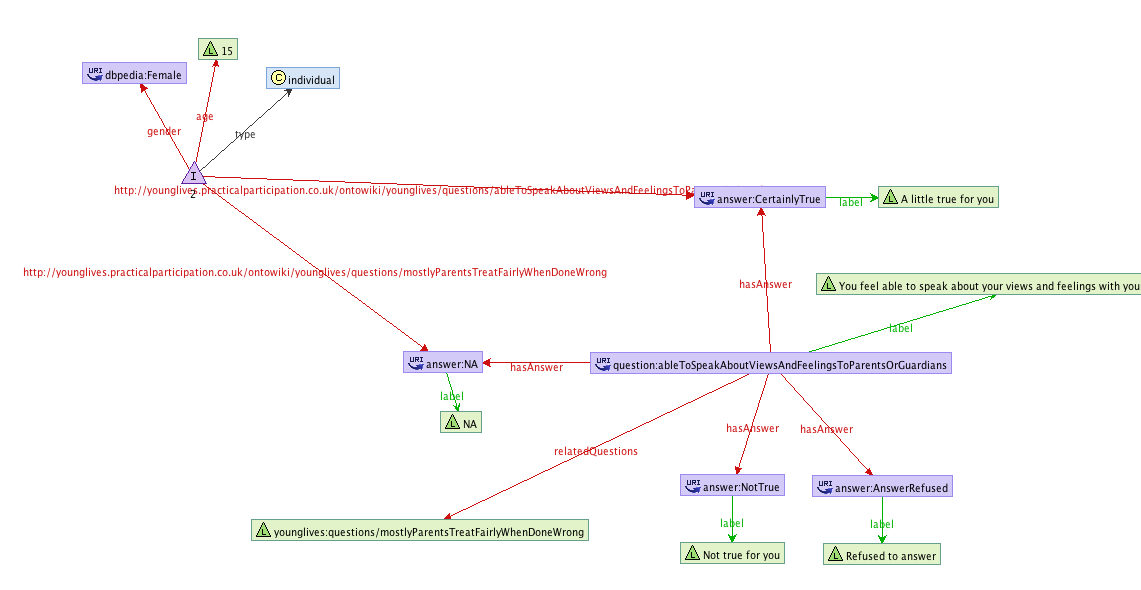
Questions
- Is this making the right sort of use of predicates? Should there be a 'blank node' for each question asked which directly links to the question and the value? Or is it ok to relate the individual to their response value using the question as a predicate?
- Should answers be related to individuals by virtue of questions, or should we create predicates (such as ableToSpeakAboutViews) and assume the value of these to be inferred by the answer to the question. We then model the responses as more definite 'properties' of individuals as opposed to propositional attitudes held by those individuals.
Further notes on modelling
There are a number of vocabularies available for statistical data.
The RDF Data Cube vocabulary provides a way of representing measures, dimensions and atributes.
- Measures are the values of observations
- Dimensions are components that identify the observations (e.g. Time; Geography etc.)
- Attributes are properties of the observed values (measurements). For example, the unit of measurement, or notes on the status of measurement (e.g. estimate / provisional).
The Data Cube vocabulary also has a concept of slices (grouping together a set of observations along a particular set of dimensions to attach further meta-data to these). For example, in Young Lives, all the observations from one country may constitute a slice against which specific meta-data for that country can be attached.
The data cube vocabulary uses SKOS to represent concepts.
DDI is a standard for micro-data (e.g. Survey data) rather than aggregate statistical data (which is the preserve of SDMX). The spssDDI packaged in R can be used to read SPSS files and write DDI files. The following example shows how to generate an DDI file from an SPSS file using R. The DDI XML may possibly be useful in generating Data Cube RDF
library(spssDDI)
data<-readSpssSav("data.sav")
sink("dataddi.xml")
writeDDI(essSample,"essSample.sav")
sink()
SDMX
Drawing on the namespaces here [1] we can use SDMX concepts for describing dimensions in our data cube which match to those used in SDMX standards. This should support comparison between summary statistics in our dataset and any from SDMX using systems.
A list of SDMX concepts can be retrieved from our SPARQL endpoint with this query [2]
Meeting Notes - 8th September 2010
Tim Davies, Anne Solon, Caroline Knowles present (TD's notes)
Data structure
- Relating subjects and questions
- In effect we have a subject & responses dataset - and a questions dataset;
- Many of the interesting things we want to say are about questions - e.g. how were they derived; what associated research is there etc.
- The 'factive' nature of question responses will vary:
- Some questions are always based on researcher measurements (e.g. Counting the number of rooms in a house)
- Some questions are sometimes verified (e.g. asking to see an ID Card to record an ID number also giving access to check age)
- Sometimes this will vary by country (e.g. no ID cards in Ethiopia)
- The reliability of some questions will vary according to culture and researcher activity
- In effect we have a subject & responses dataset - and a questions dataset;
We can annotate questions, and potentially set the scope of those annotations by country.
Even demographic data can have caveats. E.g. in Ethiopia respondents may not be clear on their age or date of birth: may give the same age two years in a row (more than 12 months apart).
Other datasets worth looking at
The Birth to 20 project in South Africa: potentially using many of the same questions as the Young Lives project.
Also need to look for taxonomies of topics that may be relevant for categorising questions. Could look at journal key-words, with a focus on the following journals:
- Social Science and Medicine
- The Lancet
- World Health Bulletin
Linking against a journal taxonomy could be useful in creating connections between question meta-data and wider data on research.
Notes on dataset structure
The following NA/missing data codes are used:
- 77 - Not Known
- 79 - Refused to answer
- 88 - Not applicable
- 99 - Missing
The ChildID code is made up of multiple components:
- The first two digits are the Country;
- Second two digits are the siteID
- Next digit is cohort (in Peru, 1 and 8, in other countries, 0 or 1: 1 or 8 because of age when children joined study)
- Last digits are ChildID within the site (e.g. 1 - 150)
It's not possible to release the exact locations of each site for any site with < 40,000 people. However, each site does have the administrative geography hierarchy recorded for it - so we could work out what level of administrative geography gives anonymisation to all sites (e.g. County; Region) and code all sites against geography at that level of detail.
Focus for interface prototypes
Interface prototypes should focus on:
- Communicating the data;
- In order to increase data uptake - and the possibility of others creating things with the data.
Licensing
We need to think carefully about licensing. The terms and conditions of the dataset from the UK Data Archive may not be easy to render into RDF and communicate - particularly when data is being mashed up.
Tim will look into this more and prepare a brief options note.
Meeting Notes: 12th October 2010
Present: Tim Davies, Anne Solon, Caroline Knowles, Inka Barnett
We discussed data comparisons and looked at how comparisons can be made across statistics with the same topic and subject but from different datasets: for example, displaying the statistics for smoking prevalence in a Young Lives dataset, with those in a WHO dataset for a country, or in other micro-data.
To do this we will need to provide rendering of those datasets (or at least, summary statistics) in our data store.
This means we need to:
- Generate summary statistics from the Young Lives data for information such as smoking prevelance.
- Potentially generated using a SPARQL Construct Statement;
- Modelled as a data-cube with a number of key dimensions;
- Age (range?)
- Gender - (sdmx-code)
- Location -
- Model a few other datasets along similar lines...
- Include brief annotations about those datasets...
Develop an interface that will display side-by-side any summary statistics that:
- Have the same measure...
- Match on at least one or two dimensions...
E.g.
@prefix yls: <http://data.younglives.org.uk/statistics/>.
yls:refAges a rdf:Property, qb:DimensionProperty;
rdfs:label "Reference Ages"@en;
rdfs:subPropertyOf sdmx-dimension:refPeriod; # <-- Find correct SDMX way of representing age...
rdfs:range interval:Interval;
qb:concept sdmx-concept:refPeriod .
yls:refPeriod a rdf:Property, qb:DimensionProperty;
rdfs:label "reference period"@en;
rdfs:subPropertyOf sdmx-dimension:refPeriod;
rdfs:range interval:Interval;
qb:concept sdmx-concept:refPeriod .
yls:refArea a rdf:Property, qb:DimensionProperty;
rdfs:label "Area statistic refers to"@en;
rdfs:subPropertyOf sdmx-dimension:refArea;
rdfs:range admingeo:UnitaryAuthority; #<---- Find correct Admin Geo...
qb:concept sdmx-concept:refArea .
yls:smokingPrevalence a rdf:Property, qb:MeasureProperty;
rdfs:label "Smoking Prevalence"@en;
rdfs:subPropertyOf sdmx-measure:obsValue;
rdfs:range xsd:decimal .
#Need to also specific that measure is a percentage... perhaps express on scale of 0 - 1.
eg:dsd-le a qb:DataStructureDefinition;
qb:component [qb:dimension eg:refArea; qb:order 1];
qb:component [qb:dimension eg:refAge; qb:order 2];
qb:component [qb:dimension eg:refPeriod; qb:order 3];
qb:component [qb:dimension sdmx-dimension:sex; qb:order 4];
# The measure(s)
qb:component [qb:measure yls:smokingPrevelance];
# The attributes
qb:component [qb:attribute sdmx-attribute:unitMeasure; qb:componentAttachment qb:DataSet;] .
yls:health-2010-statistics-smoking a qb:DataSet;
qb:structure eg:dsd-le .
yl:smoking-m-15 a qb:Observation;
qb:dataSet yls:health-2010-statistics-smoking;
yls:refArea admingeo:peru ;
yls:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
yls:refAge "15";
sdmx-dimension:sex sdmx-code:sex-M ;
yls:smokingPrevelance "0.15".
yl:smoking-f-15 a qb:Observation;
qb:dataSet yls:health-2010-statistics-smoking;
yls:refArea admingeo:peru ;
yls:refPeriod <http://reference.data.gov.uk/id/gregorian-interval/2004-01-01T00:00:00/P3Y> ;
yls:refAge "15";
sdmx-dimension:sex sdmx-code:sex-F ;
yls:smokingPrevelance "0.16".